
文字型・文字列型
Created by Masashi Satoh | 1/19/2026
タイトルイメージ出典:Tom Scogland – 投稿者自身による著作物, パブリック・ドメイン, リンクによる
はじめに
本記事は「データモデルの学び」を補強するものです。
文字型
文字型は、コンピュータに自然言語を通じた人とのインターフェイスを提供するたいへん重要な仕組みです。しかし、その原理自体はたいへん単純なものであることは、「情報処理の基礎」の項ですでに触れました。
ASCIIコードセット
ここでは実際に国際的な規格として使われている文字セットを見てみましょう。以下はラテン文字を網羅した文字セットの代表である、ASCII(アスキー)文字セットです。
| 16進数下位桁 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
| 16 進 数 上 位 桁 | 0 | 制御コード | |||||||||||||||
| 1 | |||||||||||||||||
| 2 | ! | “ | # | $ | % | & | ‘ | ( | ) | * | + | , | – | . | / | ||
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | > | = | < | ? | |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | ||
16進数表記の意味と、なぜそれを用いるのかについては説明してあるものとします。
このシンプルな文字セットは二進数7bitで表現されます。全体の見通しがよくなるように、下位4bitを横軸に、上位3bitを縦軸にして表にしたものです。たとえば、アルファベットの大文字の”M”は、16進数で4D、2進数だと1001101という値に割り当てられているわけです。
このコードセットに従って、表現したいアルファベットや記号に対応する数値をメモリー上に表現したものが文字型です。最初に、このことをしっかり踏まえておきます。
(16進数)41 → A(表現されている文字概念)
生徒たちと確認したいのは、このコードセットにおける文字の配置が16進数の20から始まっているのは、必然ではなく、0から始まっていても不都合がないということです。アルファベットの大文字、小文字の開始位置、記号の配置なども、この通りである必然性はありません。
文字コードセットの配置は、さまざまな歴史的な経緯、それを利用する企業などの利害関係、配置の美観などの文化的な要因によってこの配置に定着したのだということを知っておくのは、よいことです。そこに人間の存在が浮かび上がるからです。調べれば数多くの人間的なエピソードが見つかるでしょう。
タイプライターとコンピュータの違い

さて、ここで、古いタイプライターの写真を生徒に見せます。
ほとんどの生徒は機械式タイプライターを見たことはないでしょうから、その仕組みについても簡単に話します。現代のコンピューター端末のキーボードは、タイプライターのスタイルをそのまま踏襲していることは、すぐにわかると思います。このことに絡めて、キャリッジリターンやラインフィードなどの制御文字の意味について踏み込んでもよいでしょう。
その上で、左上に本来あるべき”1″のキーが欠けていることを生徒たちの注意を向けます。これは、キーがとれてしまった壊れたタイプライターなのでしょうか? そうではありません。これが当時の標準的なタイプライターのキー配列なのです。

「どうしてこんな配列になったのかな? 数字の1を打ちたいときは、どうしたらいい?」と質問すれば、楽しい応酬が起こるでしょう。もしかしたら、「Iとかlで代用するんじゃない?」という生徒が現れるかもしれません。
事実は実際そのとおりで、機構部品を節約するため、当時は”1″を小文字の”L”で代用していたのです。タイプライターの場合は、印影が「どのように見えるか」だけが重要だったので、このような省略が可能でした。一方、コンピュータのキーボードでは”1″を省略することは考えられません。コンピュータの場合は、数字の1と小文字のLを、その形ではなくそれぞれの文字概念と結びついた情報として処理することを求められるからです。
タイプライターは、この違いの重要性に気づくためのよい教材になるでしょう。
さて、ここでタイプライター最上段の記号の配列に注目しましょう。ASCIIコードセットの16進数20から2Fまでの記号の並びが、タイプライターの最上段に酷似していることに生徒は気づくはずです。

| ! | “ | # | $ | % | & | ‘ | ( | ) | * | + | , | – | . | / |
このように、コンピュータ技術は先行する技術や文化を常に取り入れながら、その技術を成立させるために必要な定義や規格を構築してきたのです。
メモリー上での文字の表現
このようにして定義された文字コードセットを、メモリーの上に配置することによって、コンピュータは文章を処理することができるようになります。以下は、”The quick brown fox jumps over the lazy dog.”を、ASCIIコードセットを使ってメモリー上に表現したものです。単語の区切りをわかりやすくするために、16進数20のスペースコードを黄色にしてあります。
54686520717569636B2062726F776E20666F78206A756D7073206F76657220746865206C617A7920646F672E
この16進数の数値の並びをASCIIコードセットに照らし合わせると、以下のようになっていることがわかります。
The_quick_brown_fox_jumps_over_the_lazy_dog.
こうして、コンピュータ上で自然言語を表現することが可能となりました。メモリーの上では数字の並びとなっているものが、人間が定義した文字コード表と対応する文字概念と結びつけると、人間には文章として理解されるわけです。コンピュータがこの情報を文章として理解しているわけではないことを、確認しておきましょう。
ルールづくり、規格化の重要性
もうひとつ注意を向けたいのは、文字コードセットがこの場限りの定義であれば、ほとんど実用性がないということです。企業間、国家間でその文字コードが通用するような取り決めを行い、規格となったときに初めて、文字コードは価値をもちます。
たとえば、メインフレームで使われているEBCDICコードの表を見せます。ASCIIとは似ても似つかないコード配列であることに、生徒は驚くと思います。もちろん、両者には互換性がありません。相互に文章をやりとりする際には、変換プログラムを通さなければなりません。しかしEBCDICがなぜこのような配列になったのかにも、10進計算の丸め誤差対策に使われるBCDという数値表現に基づいた開発の歴史があるけです。
このように、情報を交換するためには、情報交換する者同士による合意形成が必要なのです。
現在では、UNICODEという文字コードセットが、世界中の言語の文字情報を包摂するようになり、世界をつなぐインターネットを支える基本技術になっています。その規格策定のために、ユニコードコンソーシアムという非営利組織が設立され、言語の専門家や技術者が集まって議論が重ねられてきました。
そこには普遍主義的な理想が掲げられているわけですが、一方で、数値情報の地図の一等地を誰(どの文字)が占有するのかという領土問題に似た駆け引きがあり、複雑な構成の文字の表記方法の議論、異体字などの文字の揺らぎをどこまで包摂するのかという気が遠くなるような議論も続けられていることにも注意を向ける必要があります。思春期の生徒たちに強く訴えるテーマでしょう。
数値としての文字
さて、文字型の話題に戻りましょう。
さきほど、それぞれの文字が、どの数値に割り振られているかには大きな意味がないと述べました。特定の文字概念が特定の数値と一意に対応していることだけが重要なのです。しかし、アルファベットやひらがなの50音を人が扱う際には、abcdefg…、あいうえおかきくけこ…というように、順序づけて整理し、理解するということが行われます。この文化をコンピュータ上で表現するためには、これらの文字概念を序数に対応づけることが必要になることを確認しておきましょう。
また、文字概念が数値として表現されていることによって、アルファベットの大文字小文字の変換が計算によって可能になります。ASCIIコードセットでは、大文字のAと小文字のaの間には16進数で20、10進数で32の差があるので、32を足したり引いたりするだけで、大文字小文字の変換ができるわけです。
人にとっては、大文字小文字の変換という意味になりますが、コンピュータは指示されたとおりに計算しただけであることに注意を向けます。
そして、引き算を行うことで、文字の比較ができることは以前にも見たとおりです。検索のもっとも基本となる技術です。
では、二進数の数値を10進数の数値表現に変換するにはどうしたらよいでしょうか? 生徒たちに考えさせます。これも計算でできそうです。
そう、変換したい値を10で割ると、その余りが10進数の一桁となるので、ASCIIコードセットの0の値である16進数30、10進では48を足せば、ASCIIコードの該当する数字が手に入ります。あとは、変換したい値から先ほどの余りを引き、同じことを繰り返して桁を上位方向にずらしていけばよいわけです。
数値を文字として表記するだけで、こんなに面倒な手続き必要であることに生徒たちは驚くでしょう。きらびやかなユーザーインターフェイスの背後で、機械であるコンピュータはこのような泥臭い仕事を、指示されたとおりに愚直に遂行しているのです。それをなんとなくでも想像できるようになることが大切です。
文字列型
さきほど、文字型をメモリー上に並べて、文章を表現できることをわたしたちは確認しました。
The_quick_brown_fox_jumps_over_the_lazy_dog.
ただし、実際にこの一連の文字列扱う上で、考慮しなければならないことがあります。それは、文章によって、文字列の長さが変化することです。整数型であれば、大きさは常に一定なので、その番地から整数型の大きさのビット列を読み出せばよいだけです。文字列の場合はそれが保証されません。
文字情報も数値も、どちらもコンピュータにとってはメモリー上のパターンにすぎないわけですから、ここからここまでが文字列だよと、人間が区画整理してやらなければなりません。文字列の長さが変化しても、その長さの範囲をひとまとまりの文字情報の並びとして適切に処理可能にするには、どのような仕組みが考えられるでしょうか。
これも生徒に考えさせるとよいでしょう。
まず、文字列の先頭がどこにあるのかはわかっているものとします。
ひとつの方法は、終端キャラクターを置くという方法です。たとえば、ASCIIコードセットの制御コードが表記に使われることはないので、このうちのどれかを文字列の終点を示すマーカーとして文字列の最後に置くのです。ここでは0(制御コードのNUL)を置くことにしましょう。
The_quick_brown_fox_jumps_over_the_lazy_dog.NUL
この文字列の頭から順に追いかけていき、0が見つかったら、その直前が文字列の最後だということがわかります。
非常に単純明快ですが、この方法にはやや難点があります。文字列を先頭から終端キャラクターの出現まですべてチェックしないと、文字列の長さがわからないからです。
おそらく、生徒から声があがるでしょう。「長さの情報をセットにしたらいいんじゃない?」
その通りです。次のようなデータ構造を考えます。文字数を保持する整数型をひとつと、あとはその文字数が示す長さの文字型の列です。
文字数:44 The_quick_brown_fox_jumps_over_the_lazy_dog.
これなら、取り扱いがずっと簡単です。ほとんどの文字列型がこのようなかたちをとっています。
高度な文字列操作
では次に、一連の文字の連なりである文字列の操作について考えてみましょう。
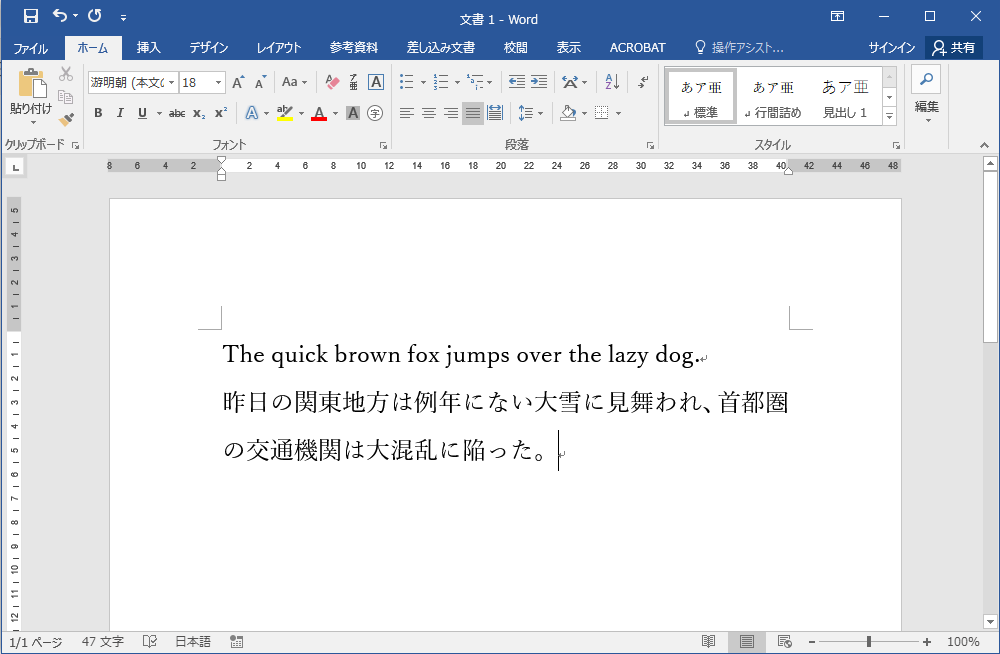
昨日の関東地方は例年にない大雪に見舞われ、首都圏の交通機関は大混乱に陥った。
上記のようにメモリに文字(実際には文字に対応するID=数値)を並べることで文字列を表現することはすでに学びました。では、上記の「関東」を「東北」に置き換えるには、どうしたらよいでしょうか?
昨日の関東地方は例年にない
↑
東北
この場合は、単純に「関東」を「東北」で置き換えればよいことがわかります。では、「関東」を「関東甲信越」に置き換えるにはどうしたらよいでしょうか?
昨日の関東地方は例年にない
↑
関東甲信越
このままでは「甲信越」の3文字が入らない!
「地方は…」以降の文字を、後ろにずらしてから空いたスペースに「甲信越」を書き込めばよいでしょう。
昨日の関東→→→地方は例年にない
↑
甲信越
では、「関東地方」を「大阪」に置き換える場合はどうでしょうか?
昨日の関東地方は例年にない
↑
大阪
今度は逆に、「は例年にない…」以降を二文字分前にずらす必要があります。まず、「関東」を「大阪」に置き換えた後に、以下の操作を行います。
昨日の関東地方は例年にない
昨日の大阪←←は例年にない
昨日の大阪は例年にない
これが文字列操作の基本的な考え方です。
ただ、この方法でワードプロセッサ・ソフトを作成するのは実用的ではありません。もしも取り扱う文章が非常に長文で、本1冊分ほどの分量だったとしたらどうでしょうか?
上記の文章の後ろにもしたくさんの文章が続くとすれば、その大量の文字列を延々と2文字分前方にずらす作業が発生します。小さな変更の度に、このような大量の作業が毎回発生するのですから、明らかに不効率です。
この、文字を移動するという作業は、コンピュータにとっては、メモリの内容をとりだしては書き込むという作業の繰り返しを意味します。
このような作業は、非常に高性能なコンピュータでさえ苦手とする作業なのだということを生徒と確認しましょう。なぜなら、現代の高性能なCPUの処理速度に比べると、メモリーの読み書き速度は非常に遅いからです。遅いメモリーから読み出し、遅いメモリーに書き込むことを繰り返すのですから、いくらコンピュータが高性能でもどうにもならないのです。
このような操作を「コストが高くつく操作」という言い方をしますが、これは無駄が多い操作とも言えるでしょう。
では、上記のような操作を「低コスト」で行うことができないでしょうか?
このように、大きな情報の塊を効率よく取り扱う目的で考えられた仕組みにポインターがあります。
ポインターはIDとよく似ています。IDは特定の概念を示す記号でしたが、ポインターはメモリー上の特定の情報が置いてある場所=番地を保持しています。ポインターの保持する値が示す番地に、目的の情報が置かれているわけです。
ポインターは番地情報しかもっていないので、そこに置かれている情報の種類や大きさは、別の情報として管理する必要があります。この考え方に従って、先の文章の例をメモリー上に表現してみましょう。
「昨日…」のアドレス ポインター型の情報
「昨日…」文字数:38 整数型の情報
↓ 2つの情報が以下の文字列の場所と長さを示している
昨日の関東地方は例年にない大雪に見舞われ、首都圏の交通機関は大混乱に陥った。
文字列を文字列の実体と、その文字列の先頭の位置(番地)を示すポインタと、そしてその文字列の文字数の数値情報のセットで表現していることになります。この例では、ポインタ型のデータが示すアドレスに「昨日の」で始まる文字列情報が納められており、その長さは38文字であるということを示しています。
この3つの情報のセットを文字列型と考えます。浮動小数点型が指数部と仮数部のセットで構成されていたのと同じ考え方です。(以前に学んだように、文字列型の表現方法は他にもありますが、文字列を扱う型という意味で、どれも文字列型と呼びます。)
このような情報セットで文章を扱うことで、文字列操作の効率が飛躍的に高まります。実際の操作の様子を見てみましょう。
これらの情報を使って、文字列中の「関東」を「関東甲信越」に置き換えてみます。まず、追加で挿入する「甲信越」の文字列を文章とは別に用意します。
「甲信越」のアドレス文字数:3
甲信越
次に、文字列「昨日の…」を、「甲信越」を挿入する「地方は…」の位置で分割します。やり方は簡単です。「地方は…」に対応するポインタを新たにつくり、分割点で区切られた文字列の文字数を計算し直して代入すればよいのです。
「昨日の…」のアドレス文字数:38
昨日の関東地方は例年にない…
↑ ここで分割する
分割されて、新しく「地方は…」で始まる文字列ができました。
「地方は…」のアドレス文字数:33 (38-5)
地方は例年にない例年にない大雪に見舞われ、首都圏の交通機関は大混乱に陥った。
あとはもとの文字列「昨日の…」の文字数を分割後の文字数に修正するだけです。ここでは5文字です。
「昨日の…」のアドレス文字数:5
昨日の関東
この簡単な操作によって、わたしたちは「昨日の…」で始まる長い文章を、「地方は…」の部分で2つの文字列に分割したことになるのです!!
その上で、このふたつの文字列の間に「甲信越」という文字列を挿入する方法を考えればよいのです。
ここで注目したいのは、ポインターと文字数情報は、文字列の実体と同じ場所に置いておく必要がないということです。ポインターが文字列の置かれた場所を把握しているのですから、くっつけておかなければならない理由はありません。
この性質を利用して、以下のように各文字列のポインターと文字数の情報を集めて並べてみます。
「昨日の関東」のアドレス文字数:5
「甲信越」のアドレス文字数:3
「地方は…陥った。」のアドレス文字数:33
いかがでしょうか。この3つの文章をつなげたものが、わたしたちが目指した「関東」と「地方」の間に「甲信越」を挿入した文章のゴールなのです。
「ひとつの文章を分割して間に単語を挿入する」と言っても、文字情報自体を動かす必要がないことが理解されるでしょう。上記の3つの文字列を一続きの文章として扱うことができればそれでよいのです。ポインタを順番に追っていき、ポインタが示す文字列を読み出して、次々につなげていけばよいわけです。
一続きであろうが、分割されていようが、さほど違わない作業量で大きな文字列を扱える仕組みがこれでできました。
文章全体の文字数も、すべての文字を数え上げる必要はなく、各ポインタとセットになった文字数情報を足せば求まります。
何らかの事情で分割された文字列をひとまとめにしたければ、全体の文字数分のメモリー領域を確保した上で、分割された文字列を順番にコピーします。
全体の文字数にあわせてメモリーを確保
確保したメモリー領域のアドレス確保した文字数:41(5 + 3 + 33)
________________________________________
コピーする
「昨日の関東」のアドレス文字数:5
↓
昨日の関東____________________________________
次をコピーする
「甲信越」のアドレス文字数:3
_____ ↓
昨日の関東甲信越________________________________
その次をコピーする
「地方は…陥った。」のアドレス文字数:33
________ ↓
昨日の関東甲信越地方は例年にない大雪に見舞われ、首都圏の交通機関は大混乱に陥った。
目的の結果が得られた
新しい「昨日の…」のアドレス「昨日の…」文字数:41
昨日の関東地方は例年にない大雪に見舞われ、首都圏の交通機関は大混乱に陥った。
このように、ポインター型、整数型、文字型を組み合わせることで、たいへん柔軟な文字列操作の仕組みを構築することができます。文字列のように、長さが変化するような情報を扱う際には、必ずポインター型が活躍しています。
どんな巨大なデータも、ポインターひとつで切ったり、つなげたり、順番を入れ替えたりできるのですから、たくさんの情報を扱う上で欠くことのできない技術です。ブロックチェーン技術なども、その発想自体はポインター型を使ったリスト構造に原型があると言えるでしょう。
ポインター型については、別項でもう少し掘り下げようと思います。
最後に、もしも時間に余裕があり、生徒たちの関心が高いようであれば、メモリーアロケーションの仕組みに言及してもよいでしょう。上記の例では、文章の結合の際に確保するメモリー領域がどのように準備されるのか、また、結合済みの文章の断片を解放するにはどのような処理が必要なのかに触れればよいでしょう。
以上、文字型・文字列型がどのようなものであるかを見てきました。
見てきたように、コンピュータのなかでは、複数の情報を組み合わせたデータ構造を使って世の中の事象や概念が表現されています。メモリという、それ自体は意味をもたないマス目を人々は意味づけ、秩序づけ、様々な仕組みを生み出してきました。ワードプロセッサも、そのような成果のひとつです。
ここで、ワードプロセッサを実際に動かしてみると、この学びが強く生徒たちに印象づけられると思います。ワードプロセッサの背後では、利用者がキーボードから入力する文章を、ここで見たような仕組みによって操作しているのです。
- ヴァルドルフ/シュタイナー教育におけるICTカリキュラムの骨格を形づくる
- The History of Computers(Currently being produced)
- リレーによる加算機回路製作の詳細
- シーソーによる論理素子
- クロックとメモリー
- リレーの起源と電信装置
- シーケンサーについて
- About the Battery Checker(Currently being produced)
- インターネット
- データモデルの学び
- Learning Programming and Application Usage Experience(Currently being produced)
- Human Dignity and Freedom in an ICT-Driven Society(Currently being produced)

コメント